
If you regularly read scholarly papers, you likely use a reference manager to maintain your personal library. Papernaut connects to your library to find online coverage and discussion of your papers in blogs, forums, and mainstream media. My hope is that these discussions can provide broader perspective on research and, in some cases, be the spark that starts a new collaboration.
Here’s a very quick video demo. We start with a Zotero library that includes a paper from Science on the effect of pesticides on honey bees. We then connect to Papernaut, and find several discussions and articles, including one in The Guardian:
I’ve been working on Papernaut in my spare time for a few months, and I’m happy to say that it’s now open source. The project comes in two parts, and the source is on GitHub:
- Papernaut-frontend is the web frontend.
- Papernaut-engine is the feed crawler and matching backend.
If you are interested in how the application is put together, the rest of this article is a technical overview of the moving parts and how they interact.
Overview: A simple example
Let’s walk through a simplified example. Say I have only one paper in my reference manager — that paper from earlier, about the effect of pesticides on honey bees:
Henry, M., Beguin, M., Requier, F., Rollin, O., Odoux, J., Aupinel, P., Aptel, J., Tchamitchian, S., & Decourtye, A. (2012). A Common Pesticide Decreases Foraging Success and Survival in Honey Bees. Science, 336 (6079), 348-350 DOI:10.1126/science.1215039
Let’s also say that the engine is crawling content from only one source feed, ResearchBlogging.org. Among many other content items, that source feed contains a relevant entry, whose content page is on The Guardian.
We’ll look at how the engine crawls and indexes this source feed. Then, we’ll see how the frontend pulls the paper from my reference manager and asks the engine for relevant discussions.
Papernaut-engine: Loading content and identifying papers
The goal of the engine is to produce a collection of Discussion records, each
of which links to several Identifier records, representing journal papers
that are referenced from the Discussion. In our example, the Discussion is
the article in The Guardian, and the relevant Identifier is
DOI:10.1126/science.1215039. There are also intermediate objects, Page and
Link which connect Discussions to Identifiers.
The engine consists of two main parts: loaders (which are Ruby classes), and the query API (a Rails app). For loading, it also depends on an external running instance of the Zotero translation-server.
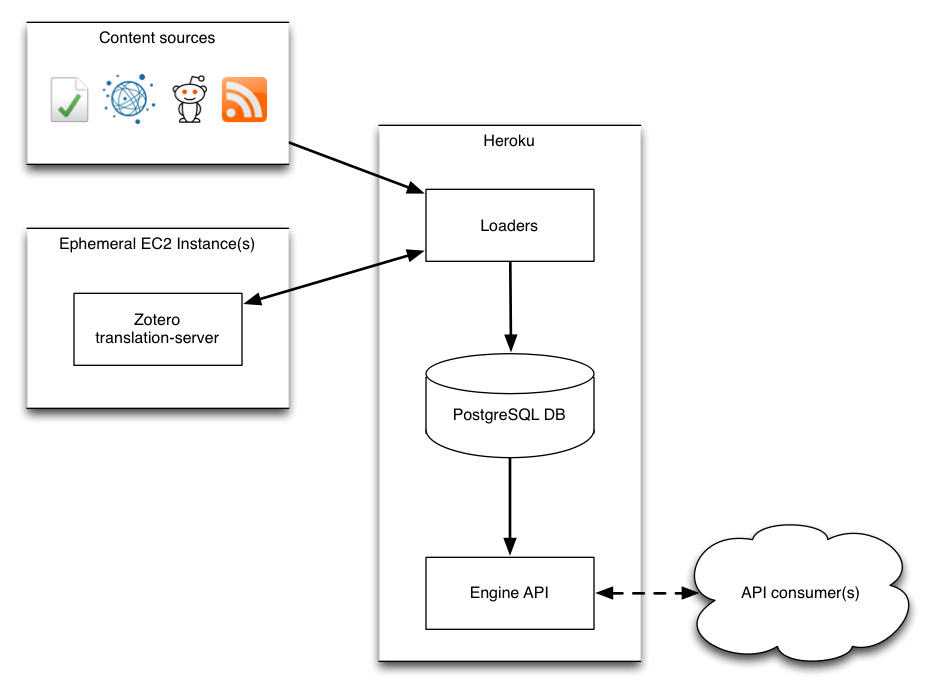
Loading content by crawling feeds
The loaders load discussion candidates from feeds and archives, extract outbound links, and store these in the database.
In the first step, I invoke the ResearchBlogging.org loader to crawl and index the most recent 100 pages of their archives:
[engine] rails runner "Loaders::ResearchbloggingWebLoader.new(100).load"
This will load a large number of Discussion entries into the database, with
zero or more Page entries for each Discussion, corresponding to outbound
links.
At this point, the engine database contains the Discussion:
#<Discussion id: 3424,
url: "http://www.guardian.co.uk/science/grrlscientist/2012/may/08/1",
title: " Bee deaths linked to common pesticides | video | G...", ...>
and the linked Page entries:
[#<Page id: 7531, url: "http://dx.doi.org/10.1126/science.1215039", ... >,
#<Page id: 7532, url: "http://pubget.com/doi/10.1126/science.1215039", ... >,
#<Page id: 7533, url: "http://dx.doi.org/10.1126/science.1215025", ... >,
#<Page id: 7534, url: "http://pubget.com/doi/10.1126/science.1215025", ... >]
Identifying papers via the Zotero translation-server
The engine determines which outbound links (or Pages) are academic papers by
issuing calls to the
Zotero translation-server HTTP API.
The translation-server is a third-party project from open-source reference
manager Zotero. It examines a given URL and, if
that page contains an academic paper, it returns common publication identifiers such as
DOI or
PMID.
The translation-server wraps the Zotero translators, a set of JavaScript scripts that do the heavy lifting of parsing a webpage and attempting to identify it as one or more academic publications. These translators are maintained by the community, keeping them fairly up-to-date with publishers. The translation-server uses XULRunner to run these scripts in a Gecko environment, and makes them available through a simple HTTP API:
[~] ~/dev/zotero/translation-server/build/run_translation-server.sh &
zotero(3)(+0000000): HTTP server listening on *:1969
[~] curl -d '{"url":"http://www.sciencemag.org/content/336/6079/348.short","sessionid":"abc123"}' \
--header "Content-Type: application/json" \
http://localhost:1969/web | jsonpp
[
{
"itemType": "journalArticle",
"creators": [
{ "firstName": "M.", "lastName": "Henry", "creatorType": "author" },
{ "firstName": "M.", "lastName": "Beguin", "creatorType": "author" },
{ "firstName": "F.", "lastName": "Requier", "creatorType": "author" },
{ "firstName": "O.", "lastName": "Rollin", "creatorType": "author" },
{ "firstName": "J.-F.", "lastName": "Odoux", "creatorType": "author" },
{ "firstName": "P.", "lastName": "Aupinel", "creatorType": "author" },
{ "firstName": "J.", "lastName": "Aptel", "creatorType": "author" },
{ "firstName": "S.", "lastName": "Tchamitchian", "creatorType": "author" },
{ "firstName": "A.", "lastName": "Decourtye", "creatorType": "author" }
],
"notes": [],
"tags": [],
"publicationTitle": "Science",
"volume": "336",
"issue": "6079",
"ISSN": "0036-8075, 1095-9203",
"date": "2012-03-29",
"pages": "348-350",
"DOI": "10.1126/science.1215039",
"url": "http://www.sciencemag.org/content/336/6079/348.short",
"title": "A Common Pesticide Decreases Foraging Success and Survival in Honey Bees",
"libraryCatalog": "CrossRef",
"accessDate": "CURRENT_TIMESTAMP"
}
]
There are several useful standardized identifiers here – DOI, URL, and ISSN.
So, continuing with our example from above, I’ll next start the Zotero translation server and identify the pages:
[engine] ~/dev/zotero/translation-server/build/run_translation-server.sh &
zotero(3)(+0000000): HTTP server listening on *:1969
[engine] rails runner "ParallelIdentifier.new(Page.unidentified).run"
The engine issues calls to the translation-server and records new Identifiers.
Now, the Page entries we previously crawled:
[#<Page id: 7531, url: "http://dx.doi.org/10.1126/science.1215039", ... >,
#<Page id: 7532, url: "http://pubget.com/doi/10.1126/science.1215039", ... >,
#<Page id: 7533, url: "http://dx.doi.org/10.1126/science.1215025", ... >,
#<Page id: 7534, url: "http://pubget.com/doi/10.1126/science.1215025", ... >]
have corresponding Identifier records:
[#<Identifier id: 1819, page_id: 7531, body: "DOI:10.1126/science.1215039" ...>,
#<Identifier id: 1820, page_id: 7531, body: "URL:http://www.sciencemag.org/content/336/6079/348" ...>],
#<Identifier id: 1821, page_id: 7533, body: "DOI:10.1126/science.1215025" ...>,
#<Identifier id: 1822, page_id: 7533, body: "URL:http://www.sciencemag.org/content/336/6079/351" ...>,
Two of the four pages were identified (7531 and 7533), and both of those
pages received two identifiers apiece. This means that the Guardian Discussion
actually referenced two different papers, not just the one we’re interested in.
Now that there is a link between the paper in question and this discussion page, we are ready to visit the frontend.
Papernaut-frontend: importing libraries, finding discussions
The frontend works in two distinct phases: first, it helps you import papers from your reference manager. Second, it shows you discussions for those papers.
You can import your papers via the
Zotero API or
Mendeley API by giving Papernaut access to your
libraries via OAuth. This happens with
omniauth-zotero and
omniauth-mendeley
libraries, followed by the
ZoteroClient and
MendeleyClient
classes.
Alternatively, you can import papers from most reference management software by
exporting and uploading a .bibtex
file. Papers and their identifiers are then extracted with the
BibtexImport
class.
Many papers will have multiple identifiers, and the frontend attempts to clean and validate your papers’ identifiers as best it can in an attempt to find the best matches.
Once your papers are loaded into the frontend, it
issues requests to the papernaut-engine query API
to find discussions that match papers in your library.

The interface between the frontend and the engine are Identifier strings,
which take a type/value form:
DOI:10.1038/nphys2376ISSN:1542-4065PMID:10659856URL:http://nar.oxfordjournals.org/content/40/D1/D742.full
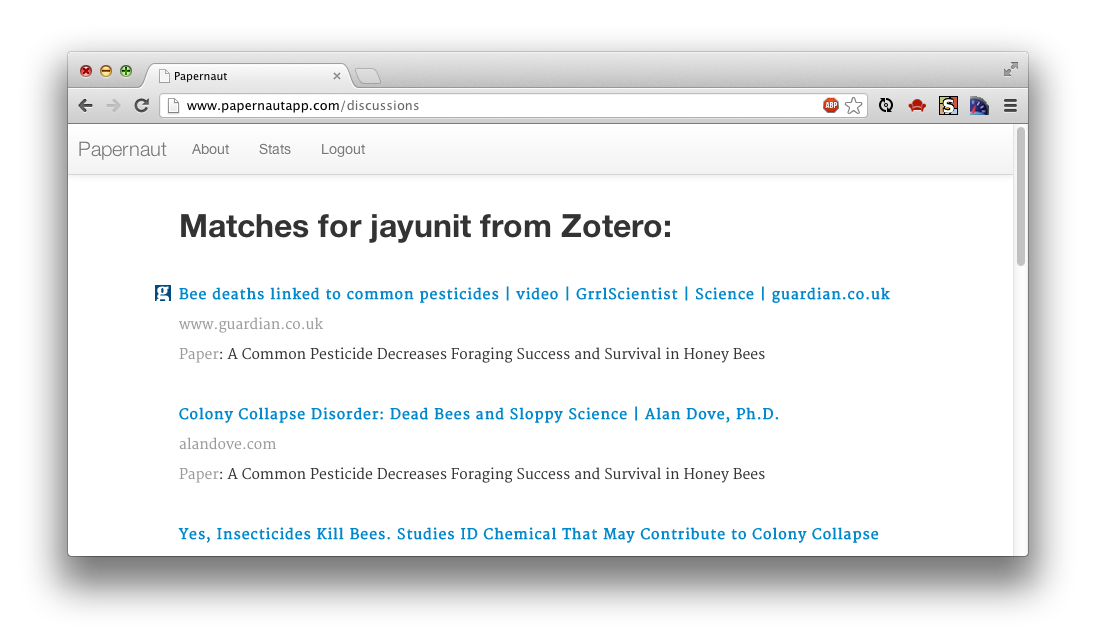
So, in our example video above, we authenticate via Zotero and authorize
Papernaut’s API access via OAuth. The frontend extracts our library of papers
from Zotero and stores their Identifiers locally. It issues requests to the
engine’s query API for matching discussions, and displays those to the end
user:
Deployment
In production, the Papernaut engine and frontend are deployed to Heroku. The translation-server is deployed to EC2. I spin it up and run the loaders periodically, to reduce hosting overhead.
There is a DEPLOY.md file for both
the frontend
and the engine
that goes into further detail.
Next steps
I’m excited to see what kinds of results people get with Papernaut, but it’s still very early software. I look forward to making a variety of improvements.
I’d really like to add a bulk request API endpoint to the engine, so that the frontend can discover discussions in a single HTTP request, rather that one request per paper. That’s a big performance hit, and the user experience right now for large libraries is that the frontend just hangs for a while.
On the engine side, I’d like to do a better job of culling false positives in the matching engine, and of contributing to Zotero’s translators to improve the match rate. I think the primary issue there is that the translator-server actually only runs a subset of all the Zotero translators, as some declare that they only work inside a real browser context (see “browserSupport”).
I’d like to get a larger sample set of BibTeX files to try, as there are probably edge cases and assumptions in the importer waiting to be hit.
I’d also like to background some of the tasks in the frontend’s import process; validating DOIs is a big one there. Ideally, the whole library import would be backgrounded, and the user interface would be notified when the import is complete.
Currently, some matches are missed because the engine and frontend have different identifiers for the same paper – say a DOI and a PMID. I also have an experimental branch that cross-references papers with the crossref.org API, which yields more complete information. Ideally that would happen in the engine. I’ve also seen some library management and import tools that use Google Scholar to improve matching and identification.
After that, I’d like loaders to run semi-continuously instead of manually, and to have more robust infrastructure around paper identification.
In the long term, it would be interesting to try and bring the discussion matching experience directly into reference managers. This is one reason why I provide the engine query API separately from the frontend.
Conclusion
I’m most interested in hearing feedback from people. Is this useful to you? If you use a reference manager, give Papernaut a spin and let me know how it goes.